前言:这篇文章是Dedecms采集功能使用方法的第二篇,主要目的是采集含有分页的普通文章,并使用简单的过滤规则。这次选取的目标站点是中国网管联盟网络技术频道的网络协议栏目,网址是“http://www.bitscn.com/network/protocol/”。本文共分为三节,第一节,主要是介绍新增采集节点中的第一步:设置基本信息及网址索引页规则;第二节,主要是介绍新增采集节点中的第二步:设置字段获取规则;第三节,主要是介绍如何采集指定节点和如何导出采集内容。对于编写采集规则中一些基本的操作,本文将一带而过或不再涉及,如有疑问可参见文章“Dedecms采集功能的使用方法 --- 不含分页的普通文章的采集”。
下面进入第一节。
建立一个新的普通文章型节点,并进入“新增采集节点:第一步设置基本信息及网址索引页规则”如(图1)所示,
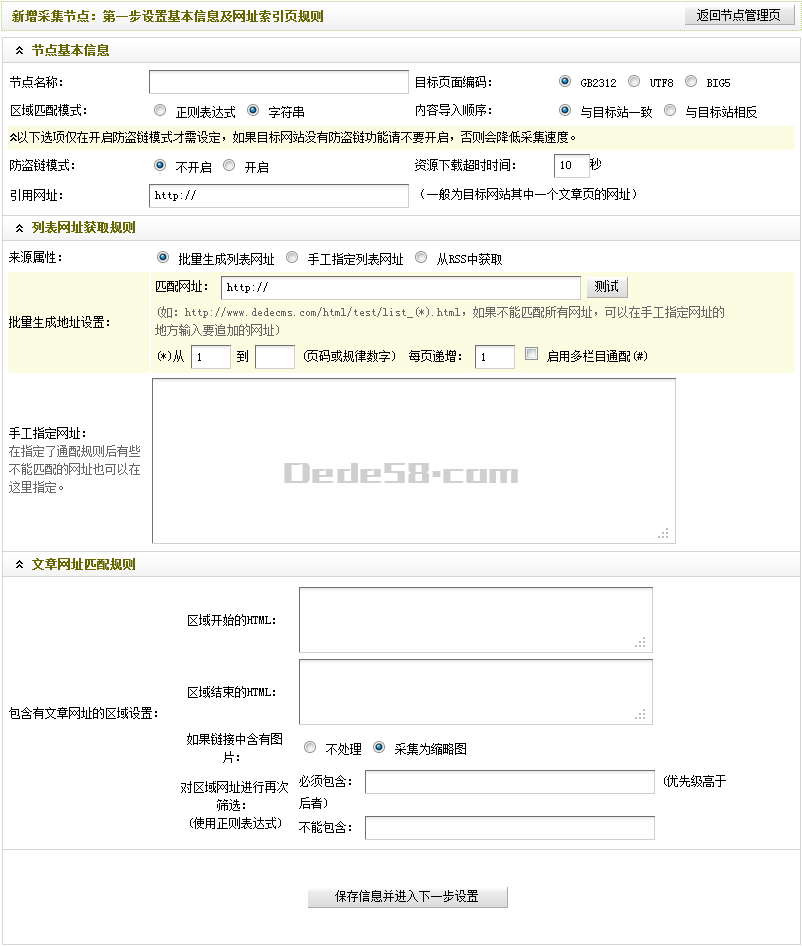
图1-新增采集节点:第一步设置基本信息及网址索引页规则
图2-节点基本信息
首先,定义节点名称为“采集测试(二)”。其次,查找目标页面编码。其操作步骤为:
(a)打开被采集的目标页:http://www.bitscn.com/network/protocol/;
(b)单击右键后选择“查看源文件”,找到“charset”, 如(图3)所示,

图3-查看源文件
其等号后面的代码就是所需的“编码格式”,这里是“gb2312”。对于“区域匹配模式”、“内容导入顺序”和“防盗链模式”,均使用默认值。
引用网址:可以选取在文章列表里出现的任意一个文章页的网址。方便起见,一般是填入文章列表中第一篇文章的网址,但是由于第一篇文章没有涉及到分页内容,为了展示如何采集分页文章,这里使用第二篇文章作为引用网址。其网址为:“http://www.bitscn.com/network/protocol/201105/193110.html”。设置后的节点基本信息,如(图4)所示,
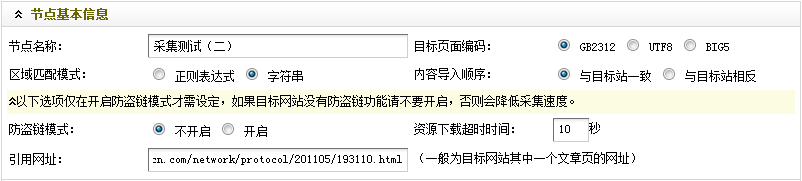
图4-设置后的节点基本信息
检查无误后,进入下一步设置。
如(图5)所示,
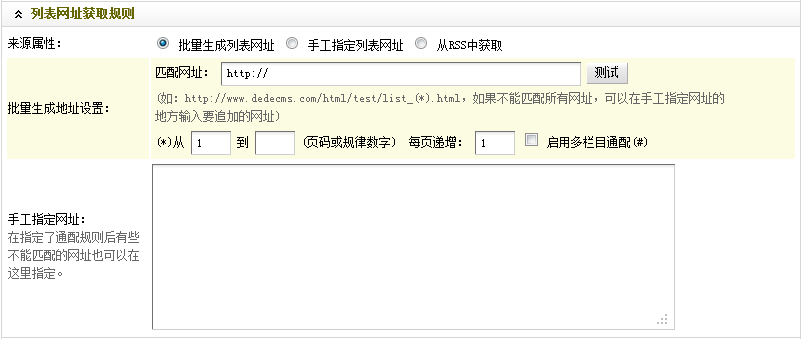
图5-列表网址获取规则
这里是设置被采集的文章列表页的匹配规则的,也是本节的重点和难点。
具体操作步骤:
(a)首先,回到已打开的文章列表页,这时浏览器的URL地址栏中显示的网址,如(图6)所示,

图6-列表首页的网址
(b)找到文章列表页的换页部分,把鼠标放在各个页码上面,同时观察其URL的变化规律。可以得出,网址的匹配规律为:“http://www.bitscn.com/network/protocol/list_(*).html“。因此,在“匹配网址”中,应填入“http://www.bitscn.com/network/protocol/list_(*).html”,为了能够快速演示采集过程,这里设定页面是从1开始到1结束,也就是说只采集第一页。
设置后的 “列表网址获取规则”,如(图7)所示,
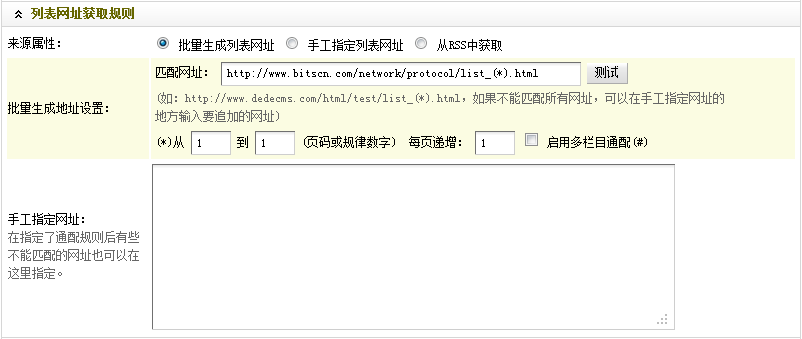
图7-设置后的列表网址获取规则
检查无误后,进入下一步设置。
如(图8)所示,
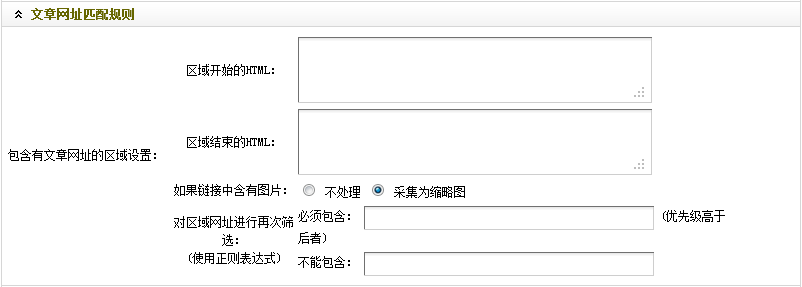
图8-文章网址匹配规则
这里是设置被采集文章列表页的匹配规则。
具体操作步骤:
(a)对于“区域开始的HTML”,可通过在打开的文章列表首页上,单击右键后选择“查看源文件”。在源文件中,找到第一篇文章的标题“OpenFlow网络是空谈吗?”,如(图9)所示,

图9-查看源文件中,第一篇文章的标题
通过观察源文件,不难看出“<div class="list-cc">”为整个文章列表的开始部分。因此,在“区域开始的HTML”中,填入“<div class="list-cc">”。
(b)在源文件中,找到最后一篇文章标题“认识多重PPP链接协议”,如(图10)所示,

图10-查看源文件中,最后一篇文章的标题
结合文章列表的开始部分并通过观察可知,“</div>”为整个文章列表的结束部分。因此,在“区域结束的HTML”中,应填入”</div>”。
设置结束后的“文章网址匹配规则“, 如(图11)所示,
0
图11-设置后的文章网址匹配规则
通过1.1.1小节、1.1.2小节和1.1.3小节,新增采集节点的第一步就已经设置完成了。设置后的结果,如(图12)所示,
1
图12-设置后的新增采集节点:第一步设置基本信息及网址索引页规则
全部完成并检查无误后,单击“保存信息并进入下一步设置“。如果之前设置正确,单击后,将会进入“新增采集节点:测试基本信息及网址索引页规则设置的网址获取规则测试”页面并看到相应的文章列表地址。如(图13)所示,
2
图13-网址获取规则测试
确定正确无误后,单击“保存信息并进入下一步设置”。否则,请单击“返回上一步进行修改“。
到这里,第一节就结束了。下面进入第二节。。。
上一篇:Dedecms采集功能的使用方法 --- 含有分页的普通文章的采集(二)
下一篇:dedecms伪静态设置以及目录链接301跳转实现方法(伪静态)
郑重声明:
本站所有内容均由互联网收集整理、网友上传,并且以计算机技术研究交流为目的,仅供大家参考、学习,不存在任何商业目的与商业用途。
若您需要商业运营或用于其他商业活动,请您购买正版授权并合法使用。
我们不承担任何技术及版权问题,且不对任何资源负法律责任。
如无法下载,联系站长索要。
如有侵犯您的版权,请给我们来信:admin@cniao8.com,我们尽快处理。